A Tale of Two Platforms
Elasticsearch 是卓越的文档索引以及全文检索工具。其基于JSON的DSL(Domain Specific query Language)简单而又强大(我觉得比SQL还差得远,好在近期新的版本发布了Elastic SQL :),使得其成为web app中集成搜索引擎的事实上的标准。那么作为analytics 后端是否胜任呢? 我们是否真的找到了一个“Hadoop”杀手呢?
首先来回忆一下一个高级“分析”系统一般都是如何构建的。开始的时候,你的app可能只需要像“mixpanel”或者“Google Analytics”这样的功能就够了,随着系统发展,产品经理的问题变得越来越难以回答: “What's the completion rate for femail Chinese users in my newly defined cohort X through the revamped user action funnel Y?” 这一问题需要cohort X的用户数据被摄取、标记出来后,再执行自定义查询来回答。为解答此问题,你需要开始收集访问日志数据,构建一个完全的“分析流水线”。经过一番调研后你会发现,有不少已有的解决方案是构建于Hadoop基础之上的,但是越来越多的开发者开始考虑使用Elasticsearch来做这件事情。怎么会这样的?一个搜索引擎真的会适合“分析”工作么?
Elasticsearch For Analytics
Elastic的ELK分析套件,包括Logstash(负责搜集服务器端日志)、Kibana(可视化窗口)在web分析应用中,得到了很多应用,因为:
1. 首先你非常容易运行起一个Elasticsearch实例
2. Elasticsearch 基于JSON的查询语言比Hadoop的MapReduce要容易操作的多
3. 对于应用开发者,Elasticsearch是工具箱中的一个已有工具,而Hadoop套件可能需要他们去全新的学习
这些原因,导致那些需要快速启动、运行分析需求解决方案的,会更倾向于选择Elasticsearch。但是一个搜索引擎,用他们执行“数据摄取”、数据分析工作,比起像Hadoop这样的具备高度扩展能力的分布式数据处理平台,其表现如何呢?
Streaming Ingestion(流式数据摄取)
很多团队,会被Elasticsearch 流式数据摄取的限制给埋进坑里。首先,Elasticsearch产品化部署,构建成集群后,一旦出现集群网络通讯中断,你可能会丢失网络中断期间100%的流式数据摄取。——现在是2019年,这个问题已经得到了基本解决。但是仍然要考虑这一点,因为,很多时候,你采集的数据都是不可“重现”的,你不可能要求用户回到你的app,重新执行一下在你机房网络故障期间的操作。Logstash没有“replay”选项,这就会要求你需要先将数据保存在真正的数据库里,比如Hadoop,MongoDB等 定时将数据推送给Elasticsearch进行分析,Elasticsearch不能构成整个分析流程的全部。好在这个缺陷可以使用fluentd来解决,我们可以基于fluentd,构建data lake,先将数据存储在hadoop中:
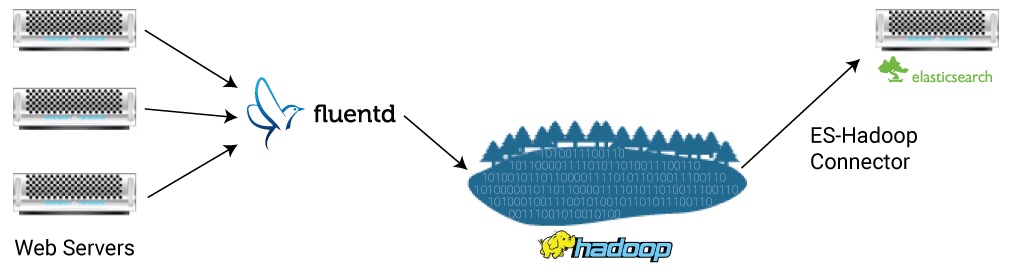
Production Resource Management
配置一个Elasticsearch集群比起你最初以为的要困难的多(Elasticsearch是这样,Kubernetes其实也是这样,一个节点玩玩so easy,配置个集群你行你上)。随着数据量增加,你不可避免的遇到很多“坑”、错误。
比如:索引分片数量必须要在初次创建索引的时候指定,索引一旦创建,就不能修改。这就要求你在刚建索引,还不知道数据会有多大的时候,先准确的猜出其大小。小数据集,大分片数会导致数据碎片化、性能下降;而为一个大数据集指定了太小的分片数量,有可能将来会遇到“分片”最大大小限制……
为了解决这个问题,Shay Banon建议大家使用时间分类的索引来存储流数据(这个我们在ELK中已经“惊奇”的见识过了),以避免单一索引数据集无休止的增长。
Schema-Free 不等于 Pain Free Uploads
Schemaless不代表你可以存入任意 key/valve 格式的数据,这是因为,Elastic针对不同的key,要分别为其创建索引。所以Elasticsearch建议你使用更generic的key/valve,

Time Consuming Bulk Uploads
另一个在Elasticsearch中存储大数据集合时会遇到的问题是批量上载数据问题。默认HTTP POST的大小限制是100Mb。一旦上传数据超过这个限制,Elasticsearch会报错中断(Out of Memory),这时候,报错之前的数据已经成功索引了,完整的数据又没有全部导入(就怕被哥哥这样闪在半道口)…… 想着就头疼。
缺少强力 “分析” 功能
Elasticsearch 的aggregation和全文检索能力,对于统计 404 错误,pageview、人群分类统计等非常高效。但是其不具备我们在传统SQL中已经常见的“窗口分析函数”功能,有了窗口函数,可以通过单个查询回答更大的问题, 例如按国家/地区划分的热门页面、关键指标上的移动平均线或触发前事件跟踪。也就是说Elasticsearch的分析能力有限制。
另外,Elasticsearch也缺少类似JOIN的操作特性。
那么Hadoop如何呢?
Hadoop是“工业级”的分布式数据处理领域的中坚力量。通过HDFS隔离“数据”和“集群状态”,master节点负责管理整个集群的状态,多个子节点仅仅负责存储数据。这些数据节点接受master节点的数据处理命令,将所有操作记录为静态日志文件。整个集群具备容错能力,备用master节点可以迅速重建系统状态,防止集群“脑裂”。
Hadoop同时具备一个完整的生态,有支持批量上载、数据摄入的组件,有支持类似传统数据库查询能力的SQL处理引擎。当然,从另一方面来说,要想运行起一套Hadoop,Zookeeper加Kafaka数据摄入agent可不是件轻松事情。所以说,Hadoop环境稳定可靠、功能强大的代价是巨大的设置以及维护成本。
Hadoop强大的MapReduce查询框架强大无匹,轻松实现各种数据“聚合”、转换工作。但是对于绝大多数简单web分析任务来说,掌握复杂的MapReduce是不必要的额外负担。这就意味着,为了避开MapReduce的复杂性,还需要为Hadoop配置一套查询引擎,比如HiveQL或者Facebook的Presto,这样分析工作就可以通过类似SQL而不是MapReduce来完成。这一引擎无比强大,但是其又更进一步的增加了整个Hadoop分析架构的复杂性。
结论: Hadoop仍然胜出
即使如此,Hadoop仍然是analytics世界的王者。Elasticsearch对于简单的web analytics来说是伟大的解决工具,但是其流式数据装载过程可能的数据丢失风险仍然是其“阿喀琉斯之踵”,缺少合适的ETL也使其难以构建完整的“分析”系统。 Elasticsearch非常适用于“简单类型”的分析场景,其即插即用的可视化(Kibana开一代潮流之先)也非常优秀,但是其似乎还没有具备所有“企业级”分析应用所必须的素质——这文章是2015年的,现在可是2019年了,Elastic 刚刚发布了7.0版本……
利用整个Hadoop生态来搭建“分析”系统仍然有着陡峭的学习曲线,但是它绝对会值得你的付出。诸如Elasticsearch-Hadoop connector工具的出现,使得我们在部署“分析”系统时会更加灵活。