……
之前我们利用DPA-Lite,已经定位到LGWR进程在特定时刻,堵塞了几十、上百个会话,导致Active Session数量在短时间内出现高峰……
之后是各种分析、诊断…… 到底是IO性能出现问题,还是Commit量太大,导致LGWR出现延迟,却是一时间无法分辨。甚至,由于REDO LOG是放在高端存储的SSD上的,SSD有无问题…… 每次“故障”也不过就10秒,想精确定位问题何其困难!
我们还是通过DPA-Lite来仔细检查,看看能不能找出一些端倪……
5月10日,16时左右,问题再现:
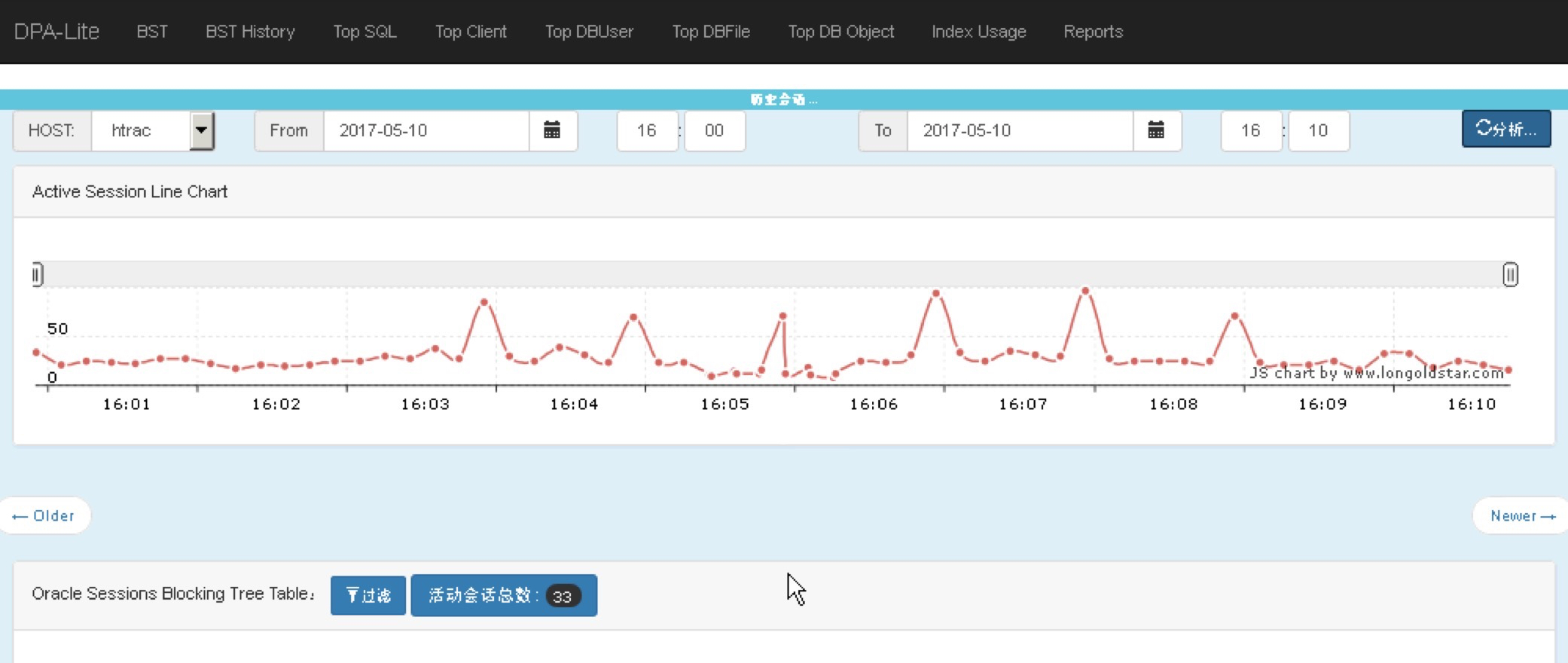
此时间段内,Active Session高峰多次出现;16:06:56秒,LGWR堵塞了68个会话;
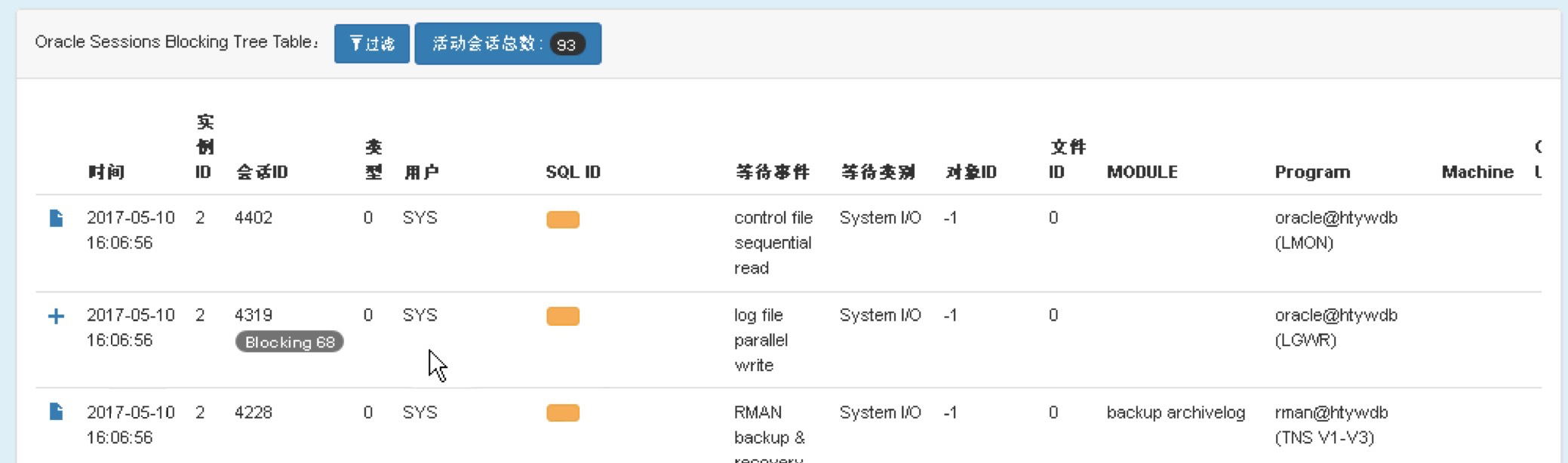
我们仔细看一看都堵塞了哪些会话,有何特点……
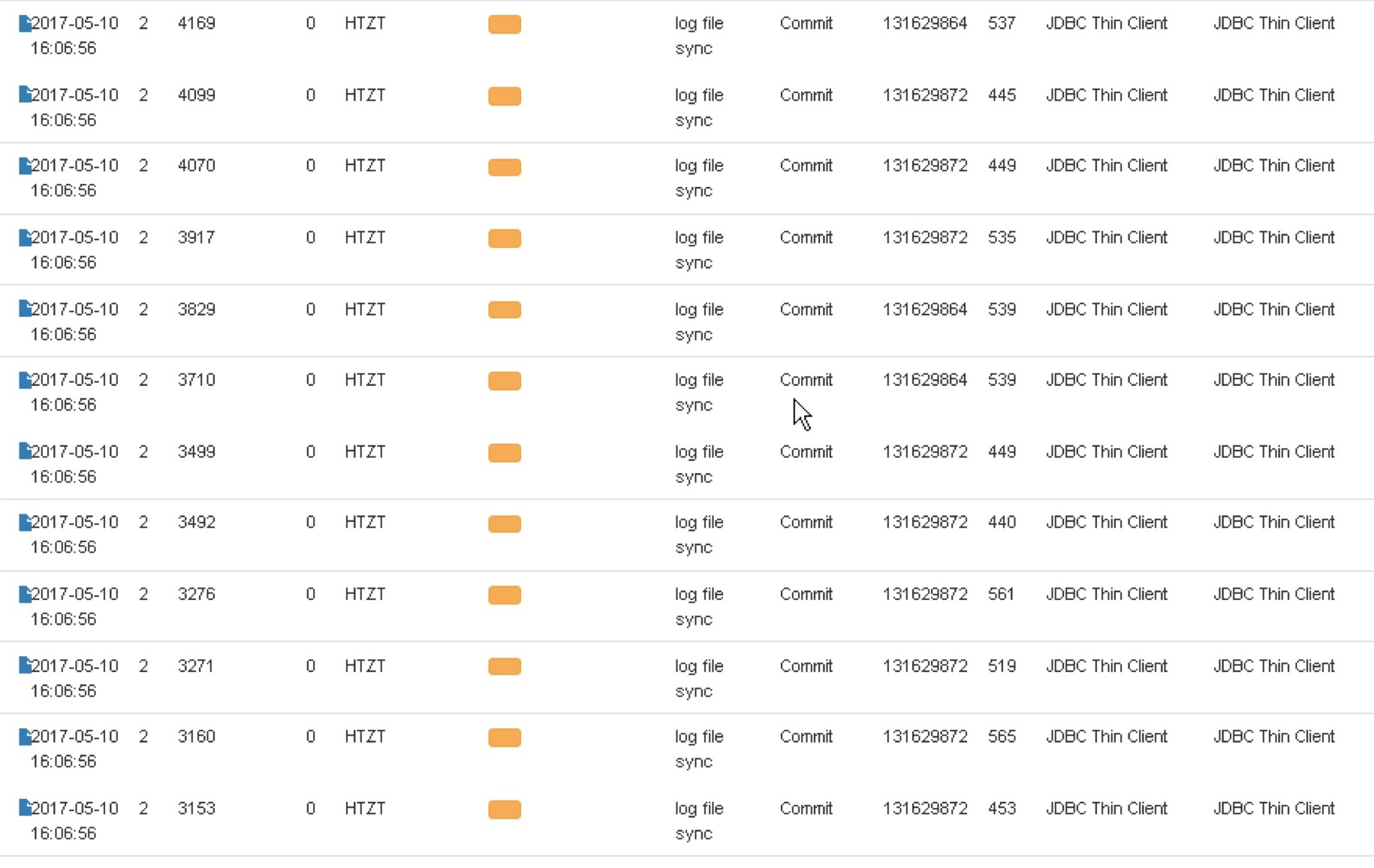
特点是: HTZT用户,通过JDBC连接的应用,在等待Commit;
当前操作的对象ID都是 131629872和131629864
通过DPA-Lite查询另外一个时间点:

再次确认了这个现象!我们再看看更早之前发生Active Session高峰时的现象(5月8日16时):
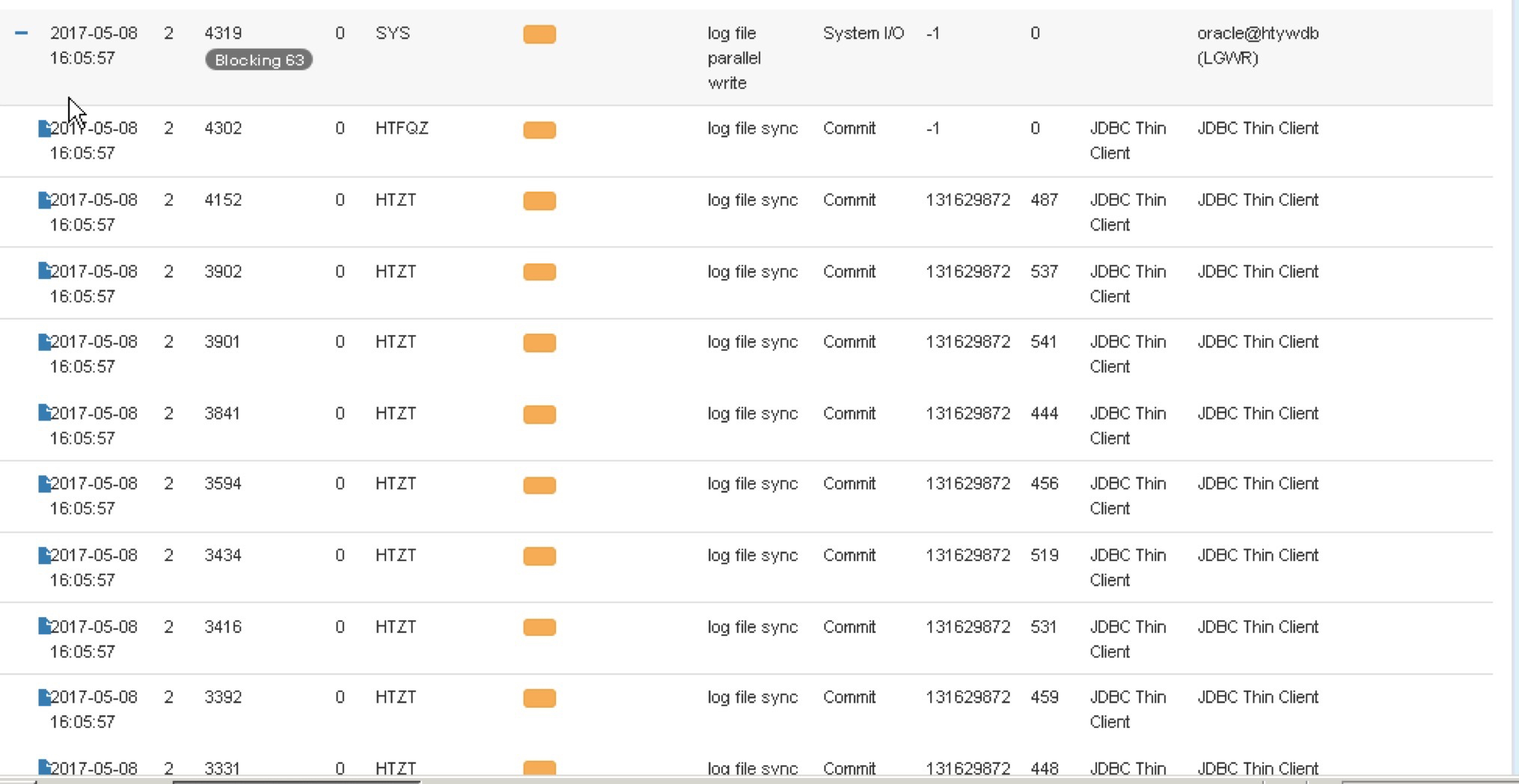
仍然是HTZT用户操作OBJECT ID 131629872 131629864时等待Commit……
我们查询数据库,确认这两个对象,发现是一张LOG(日志)表和该表上的一个索引,这个表以BLOB方式保存日志,目前数据量极大——超过300G。
使用DPA-Lite 查看对应时间段的Top Object:
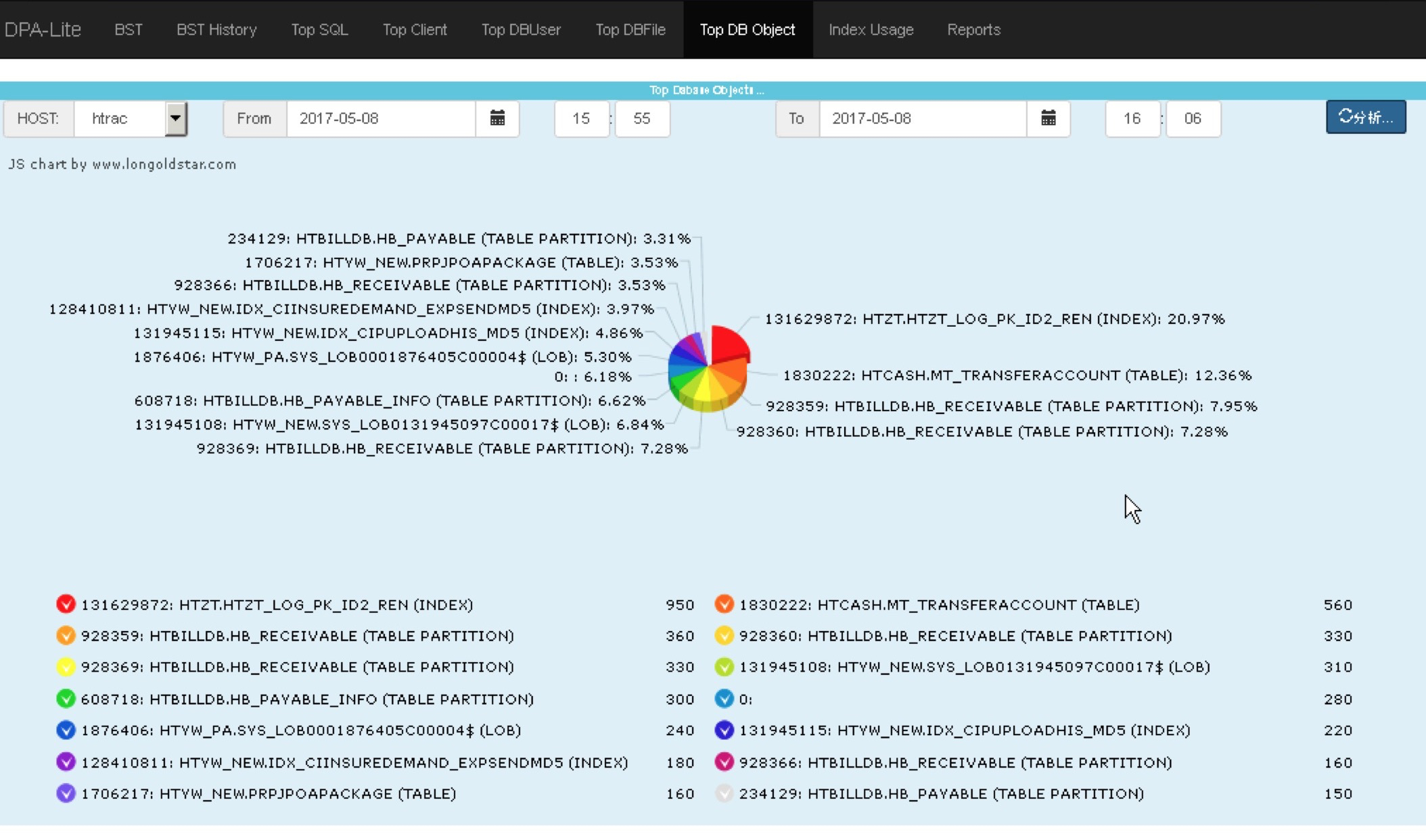
问题时间点,对于该表索引的操作,在数据库中占用资源排名第一!
存储已经用的最高端的了,解决问题就从这个日志表入手吧……
日志么,都是用来事后查询、分析使用的,我觉得存在文件系统里,利用Hadoop之类分析是最好不过的,核心数据库高端存储上存个几百GB的日志,还弄出这种问题来,赶紧迁走……
一想到拿着这些证据,一会儿让应用开发那帮哥们哑口无言我就觉得兴奋!